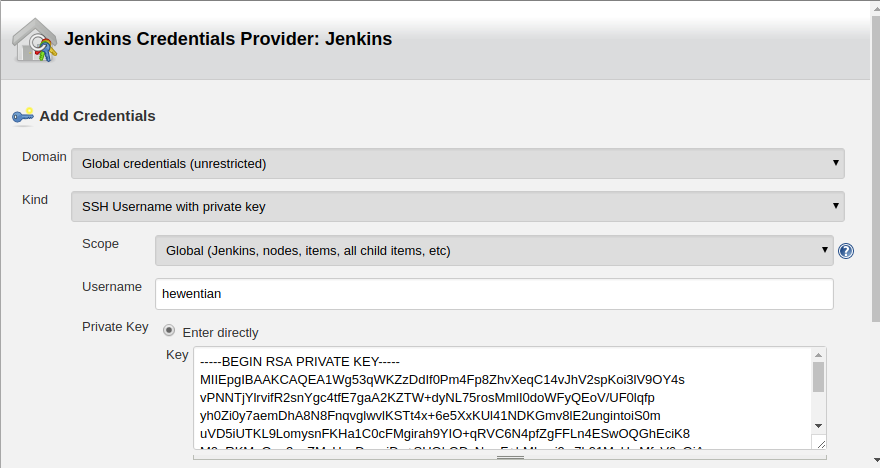
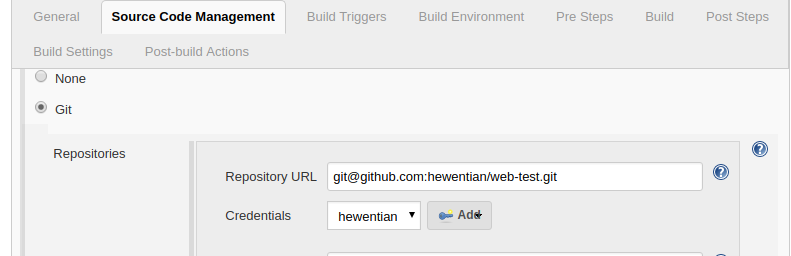
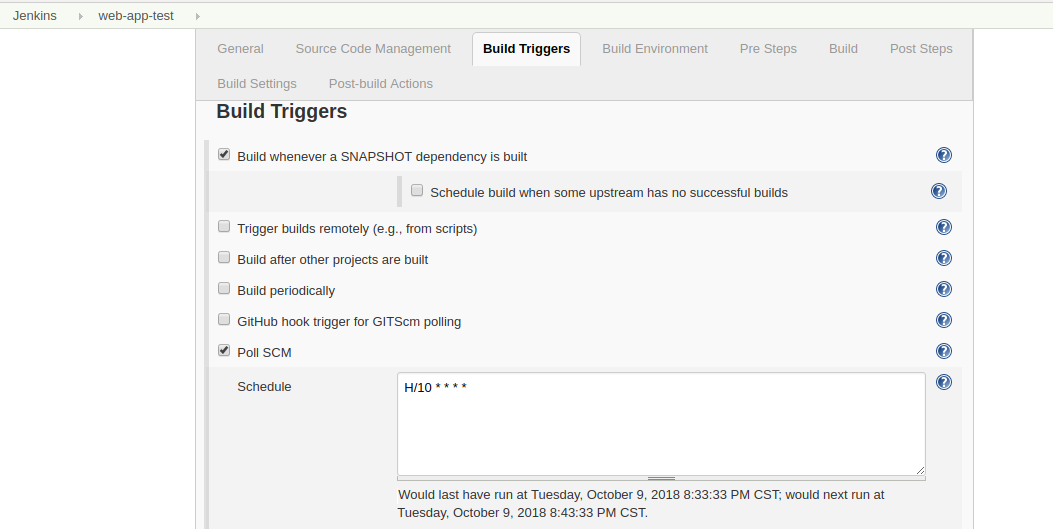
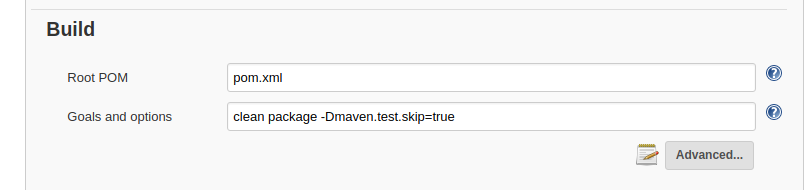
关于hadoop集群的搭建,请参考我的上一篇 hadoop 集群的搭建,这里将说说如何写一个简单的统计单词个数的mapReduce示例程序,并部署在YARN上面运行。
代码托管在:https://github.com/hewentian/bigdata
下面详细说明。
第一步:将要统计单词个数的文件放到HDFS中
例如我们将hadoop安装目录下的README.txt文件放到HDFS中的/目录下,在master节点上面执行:1
2$ cd /home/hadoop/hadoop-2.7.3/
$ ./bin/hdfs dfs -put /home/hadoop/hadoop-2.7.3/README.txt /
README.txt文件的内容如下:
For the latest information about Hadoop, please visit our website at:
http://hadoop.apache.org/core/
and our wiki, at:
http://wiki.apache.org/hadoop/
This distribution includes cryptographic software. The country in
which you currently reside may have restrictions on the import,
possession, use, and/or re-export to another country, of
encryption software. BEFORE using any encryption software, please
check your country's laws, regulations and policies concerning the
import, possession, or use, and re-export of encryption software, to
see if this is permitted. See <http://www.wassenaar.org/> for more
information.
The U.S. Government Department of Commerce, Bureau of Industry and
Security (BIS), has classified this software as Export Commodity
Control Number (ECCN) 5D002.C.1, which includes information security
software using or performing cryptographic functions with asymmetric
algorithms. The form and manner of this Apache Software Foundation
distribution makes it eligible for export under the License Exception
ENC Technology Software Unrestricted (TSU) exception (see the BIS
Export Administration Regulations, Section 740.13) for both object
code and source code.
The following provides more details on the included cryptographic
software:
Hadoop Core uses the SSL libraries from the Jetty project written
by mortbay.org.
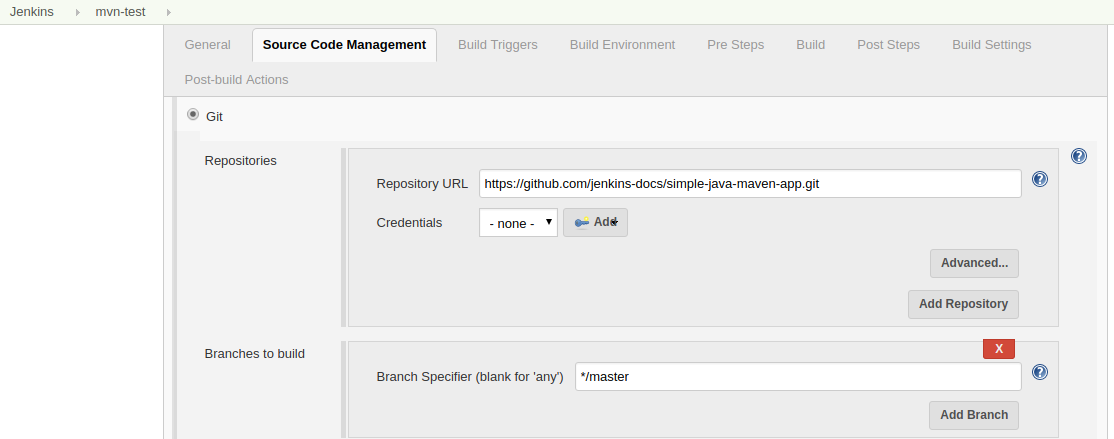
第二步:建立一个maven工程
新建一个maven工程,目录结构如下:

其中,pom.xml内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hewentian</groupId>
<artifactId>hadoop</artifactId>
<packaging>jar</packaging>
<version>0.0.1-SNAPSHOT</version>
<name>hadoop/</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
第三步:编写mapper程序
1 | package com.hewentian.hadoop.mr; |
第四步:编写reducer程序
1 | package com.hewentian.hadoop.mr; |
第五步:编写job程序
1 | package com.hewentian.hadoop.mr; |
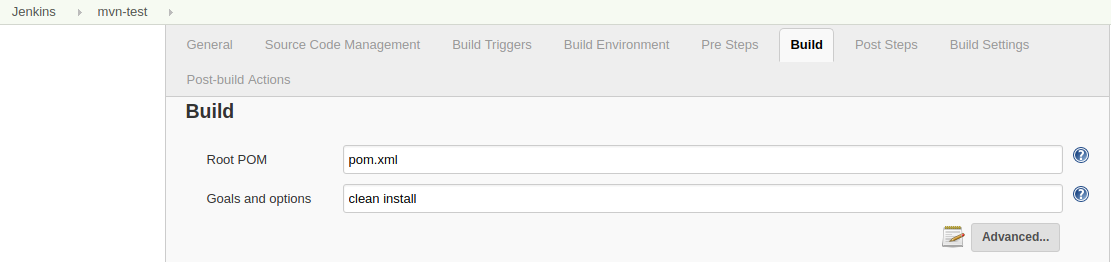
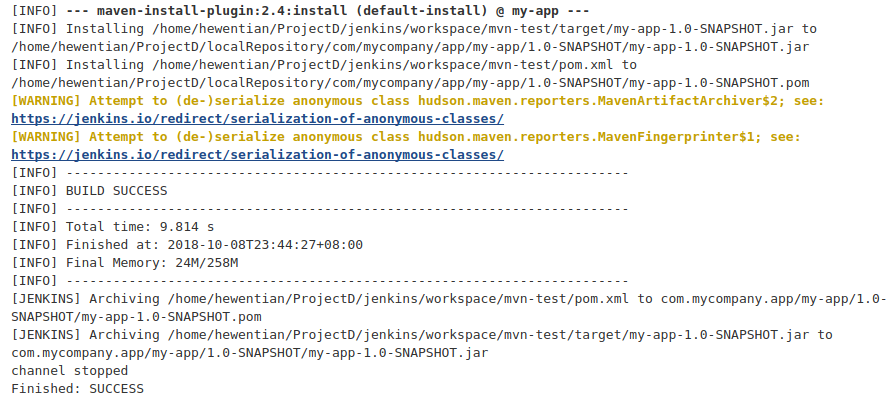
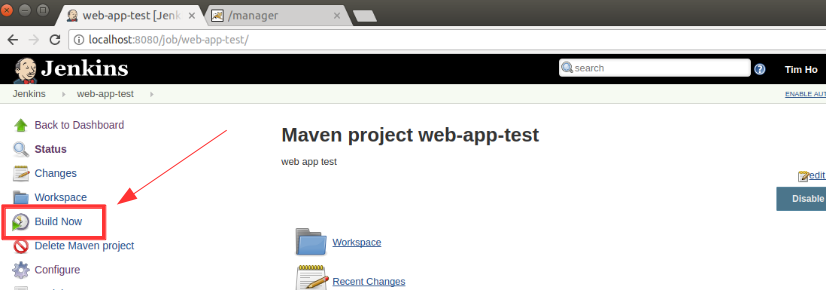
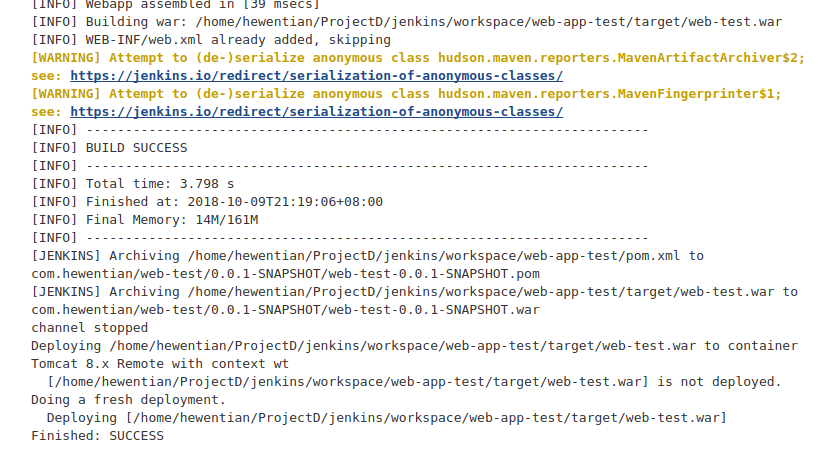
第六步:将程序打包成JAR文件
将上述工程打包成JAR文件,并设置默认运行的类为WordCountJob,打包后得文件wordCount.jar,我们将它上传到master节点的home目录下:1
$ scp wordCount.jar hadoop@hadoop-host-master:~/
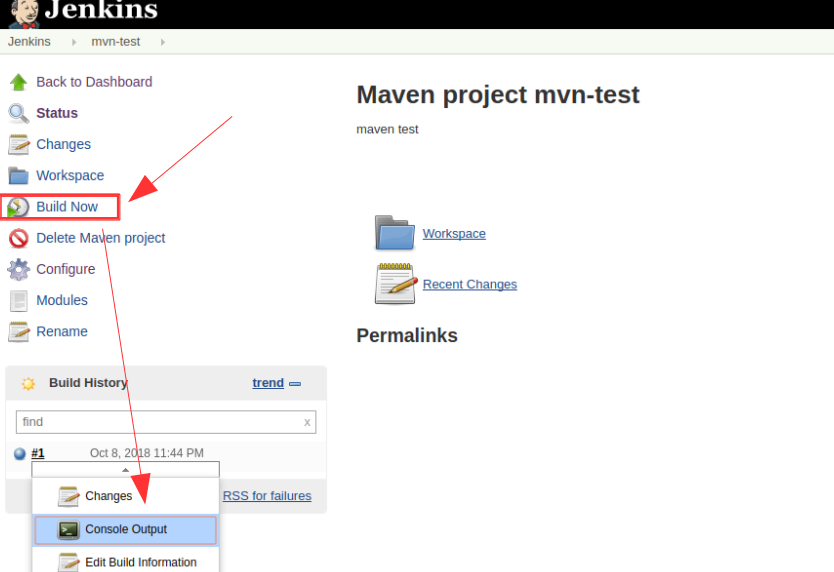
第七步:登录master节点执行JAR文件
登录master节点:1
$ ssh hadoop@hadoop-host-master
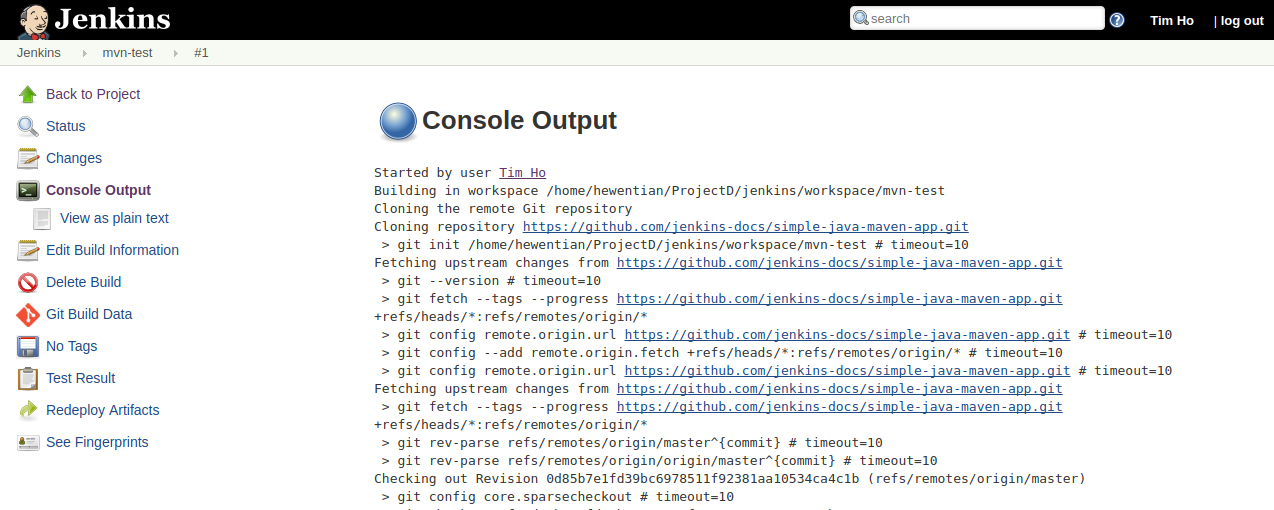
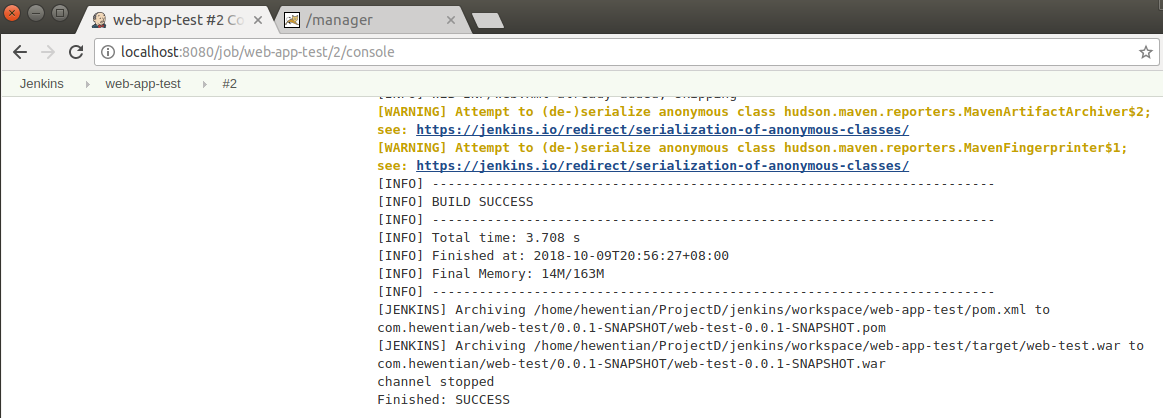
执行JAR文件,若指定的输出目录不存在,HDFS会自动创建:1
2$ cd /home/hadoop/hadoop-2.7.3/
$ ./bin/hadoop jar /home/hadoop/wordCount.jar /README.txt /output/wc/
执行过程中部分输出如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
7118/12/07 02:48:57 INFO client.RMProxy: Connecting to ResourceManager at hadoop-host-master/192.168.56.110:8032
18/12/07 02:48:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop-host-master/192.168.56.110:8032
18/12/07 02:48:58 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/12/07 02:49:00 INFO mapred.FileInputFormat: Total input paths to process : 1
18/12/07 02:49:00 INFO mapreduce.JobSubmitter: number of splits:2
18/12/07 02:49:00 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1544066791145_0005
18/12/07 02:49:00 INFO impl.YarnClientImpl: Submitted application application_1544066791145_0005
18/12/07 02:49:01 INFO mapreduce.Job: The url to track the job: http://hadoop-host-master:8088/proxy/application_1544066791145_0005/
18/12/07 02:49:01 INFO mapreduce.Job: Running job: job_1544066791145_0005
18/12/07 02:49:10 INFO mapreduce.Job: Job job_1544066791145_0005 running in uber mode : false
18/12/07 02:49:10 INFO mapreduce.Job: map 0% reduce 0%
18/12/07 02:49:20 INFO mapreduce.Job: map 100% reduce 0%
18/12/07 02:49:27 INFO mapreduce.Job: map 100% reduce 100%
18/12/07 02:49:28 INFO mapreduce.Job: Job job_1544066791145_0005 completed successfully
18/12/07 02:49:28 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=2419
FILE: Number of bytes written=360364
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2235
HDFS: Number of bytes written=1306
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=16581
Total time spent by all reduces in occupied slots (ms)=4407
Total time spent by all map tasks (ms)=16581
Total time spent by all reduce tasks (ms)=4407
Total vcore-milliseconds taken by all map tasks=16581
Total vcore-milliseconds taken by all reduce tasks=4407
Total megabyte-milliseconds taken by all map tasks=16978944
Total megabyte-milliseconds taken by all reduce tasks=4512768
Map-Reduce Framework
Map input records=31
Map output records=179
Map output bytes=2055
Map output materialized bytes=2425
Input split bytes=186
Combine input records=0
Combine output records=0
Reduce input groups=131
Reduce shuffle bytes=2425
Reduce input records=179
Reduce output records=131
Spilled Records=358
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=364
CPU time spent (ms)=1510
Physical memory (bytes) snapshot=480575488
Virtual memory (bytes) snapshot=5843423232
Total committed heap usage (bytes)=262725632
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2049
File Output Format Counters
Bytes Written=1306
等执行成功后,在master节点上查看结果(部分):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24$ cd /home/hadoop/hadoop-2.7.3/
$ ./bin/hdfs dfs -cat /output/wc/*
(BIS), 1
(ECCN) 1
(TSU) 1
(see 1
5D002.C.1, 1
740.13) 1
<http://www.wassenaar.org/> 1
Administration 1
Apache 1
BEFORE 1
BIS 1
Bureau 1
Commerce, 1
Commodity 1
Control 1
Core 1
Department 1
ENC 1
Exception 1
Export 2
For 1
Foundation 1
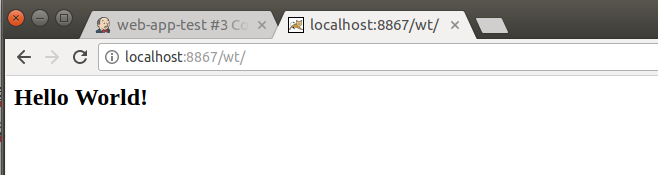
我们在浏览器中查看HDFS和YARN中的数据
在HDFS管理器中查看:

在YARN管理器中查看:

大功告成!!! (hadoop集群中的时间与我本机的时间不一致,毕竟,很久没启动集群了)