本篇将说说hadoop集群HA的搭建,如果不想搭建HA,可以参考我之前的笔记:hadoop 集群的搭建,下面HA的搭建很多步骤与此文相同。
为了解决hadoop 1.0.0之前版本的单点故障问题,在hadoop 2.0.0中通过在同一个集群上运行两个NameNode的主动/被动配置热备份,这样集群允许在一个NameNode出现故障时,请求转移到另外一个NameNode来保证集群的正常运行。两个NameNode有相同的职能。在任何时刻,只有一个是active状态的,另一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,通过手工或者自动切换,standby状态的NameNode就可以转变为active状态的,就可以继续工作了,这就是高可靠。
hadoop集群的搭建,我们将搭建如下图所示的集群,HADOOP集群中所有节点的配置文件可以一模一样的。

对上图的节点分布,如下图(绿色代表在这些节点上面安装这些程序,一般运行namenode的节点都同时运行ZKFC):

在我的笔记本电脑中,安装虚拟机VirtualBox,在虚拟机中安装四台服务器:master、slave1、slave2、slave3来搭建hadoop集群HA。安装好VirtualBox后,启动它。依次点File -> Host Network Manager -> Create,来创建一个网络和虚拟机中的机器通讯,这个地址是:192.168.56.1,也就是我们外面实体机的地址(仅和虚拟机中的机器通讯使用)。如下图:

我们使用ubuntu 18.04来作为我们的服务器,先在虚拟机中安装好一台服务器master,将Jdk、hadoop在上面安装好,然后将master克隆出slave1、slave2、slave3。以master为namenode节点,slave1、slave2、slave3作为datanode节点。slave1同时也作为namenode节点。相关配置如下:
master:
ip: 192.168.56.110
hostname: hadoop-host-master
slave1:
ip: 192.168.56.111
hostname: hadoop-host-slave-1
slave2:
ip: 192.168.56.112
hostname: hadoop-host-slave-2
slave3:
ip: 192.168.56.113
hostname: hadoop-host-slave-3
下面开始master的安装
在虚拟机中安装master的过程中我们会设置一个用户用于登录,我们将用户名、密码都设为hadoop,当然也可以为其他名字,其他安装过程略。安装好之后,使用默认的网关配置NAT,NAT可以访问外网,我们将jdk-8u102-linux-x64.tar.gz和hadoop-2.7.3.tar.gz从它们的官网下载到用户的/home/hadoop/目录下。或在实体机中通过SCP命令传进去。然后将网关设置为Host-only Adapter,如下图所示。

网关设置好了之后,我们接下来配置IP地址。在master中[Settings] -> [Network] -> [Wired 这里打开] -> [IPv4]按如下设置:

管理集群
在上面的IP等配置好之后,我们选择关闭master,注意不是直接关闭,而是在关闭的时候选择Save the machine state。然后在虚拟机中选中master -> Start 下拉箭头 -> Headless start,然后在我们实体机中通过ssh直接登录到master。1
$ ssh hadoop@192.168.56.110
我们可以在实体机通过配置/etc/hosts,加上如下配置:
192.168.56.110 hadoop-host-master
然后就可以通过如下方式登录了1
$ ssh hadoop@hadoop-host-master
在实体机中通过下面的配置,就可以无密码登录了:1
$ ssh-copy-id hadoop@hadoop-host-master
下面的操作,均是在实体机中通过SSH到虚拟机执行的操作。
安装ssh openssh rsync
如系统已安装,则勿略下面的安装操作1
$ sudo apt-get install ssh openssh-server rsync
如果上述命令无法执行,请先执行如下命令:1
$ sudo apt-get update
JDK的安装请参考我之前的笔记:安装 JDK,这里不再赘述。安装到此目录/usr/local/jdk1.8.0_102/下,记住此路径,下面会用到。下在进行hadoop的安装。
1 | $ cd /home/hadoop/ |
解压后得到hadoop-2.7.3目录,hadoop的程序和相关配置就在此目录中。
建保存数据的目录
1 | $ cd /home/hadoop/hadoop-2.7.3 |
配置文件浏览
hadoop的配置文件都位于下面的目录下:1
2
3
4
5
6
7
8
9
10
11
12$ cd /home/hadoop/hadoop-2.7.3/etc/hadoop
$ ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
配置hadoop-env.sh,加上JDK绝对路径
JDK的路径就是上面安装JDK的时候的路径:1
export JAVA_HOME=/usr/local/jdk1.8.0_102/
配置core-site.xml,在该文件中加入如下内容
1 | <configuration> |
配置hdfs-site.xml,在该文件中加入如下内容
1 | <configuration> |
至此,master中要安装的通用环境配置完成。在虚拟机中将master复制出slave1、slave2、slave3。并参考上面配置IP地址的方法将slave1的ip配置为:192.168.56.111,slave2的ip配置为:192.168.56.112,slave3的ip配置为:192.168.56.113。
配置主机名
配置master的主机名为hadoop-host-master,在master节点执行如下操作:1
2
3
4$ sudo vi /etc/hostname
修改为如下内容
hadoop-host-master
配置slave1的主机名为hadoop-host-slave-1,在slave1节点执行如下操作:1
2
3
4$ sudo vi /etc/hostname
修改为如下内容
hadoop-host-slave-1
配置slave2的主机名为hadoop-host-slave-2,在slave2节点执行如下操作:1
2
3
4$ sudo vi /etc/hostname
修改为如下内容
hadoop-host-slave-2
配置slave3的主机名为hadoop-host-slave-3,在slave3节点执行如下操作:1
2
3
4$ sudo vi /etc/hostname
修改为如下内容
hadoop-host-slave-3
注意:各个节点的主机名一定要不同,否则相同主机名的节点,只会有一个连得上namenode节点,并且集群会报错,修改主机名后,要重启才生效。
配置域名解析
分别对master、slave1、slave2、slave3都执行如下操作:1
2
3
4
5
6
7
8$ sudo vi /etc/hosts
修改为如下内容
127.0.0.1 localhost
192.168.56.110 hadoop-host-master
192.168.56.111 hadoop-host-slave-1
192.168.56.112 hadoop-host-slave-2
192.168.56.113 hadoop-host-slave-3
集中式管理集群
配置SSH无密码登陆,分别在master、slave1、slave2和slave3上面执行如下脚本:1
$ ssh-keygen -t rsa -P ""
在master、slave1上面执行如下脚本(master和slave1都作为namenode):1
2
3
4$ ssh-copy-id hadoop-host-master
$ ssh-copy-id hadoop-host-slave-1
$ ssh-copy-id hadoop-host-slave-2
$ ssh-copy-id hadoop-host-slave-3
每执行一条命令的时候,都先输入yes,然后再输入目标机器的登录密码。
如果能成功运行如下命令,则配置免密登录其他机器成功。1
2
3
4$ ssh hadoop-host-master
$ ssh hadoop-host-slave-1
$ ssh hadoop-host-slave-2
$ ssh hadoop-host-slave-3
在master、slave1上面执行如下脚本:1
2
3
4
5
6$ cd /home/hadoop/hadoop-2.7.3/etc/hadoop/
$ vi slaves # 加入如下内容
$
hadoop-host-slave-1
hadoop-host-slave-2
hadoop-host-slave-3
当执行start-dfs.sh时,它会去slaves文件中找从节点。
安装zookeeper
我们在master、slave1和slave2上面安装zookeeper集群,安装过程可以参考:zookeeper 集群版安装方法,这里不再赘述。
至此,集群配置完成,下面将启动集群。
启动集群
首次启动的时候,先启动journalnode,分别在三台journalnode机器上面启动,因为接下来格式化namenode的时候,数据会写到这些节点中:1
2
3
4
5
6$ cd /home/hadoop/hadoop-2.7.3/
$ ./sbin/hadoop-daemon.sh start journalnode
$
$ jps # 查看是否启动成功
4016 Jps
2556 JournalNode
接下来在任意一台namenode执行如下命令,我们在master中执行:1
2
3
4
5
6
7$ cd /home/hadoop/hadoop-2.7.3/
$ ./bin/hdfs namenode -format # 再次启动的时候不需要执行此操作
$ ./sbin/hadoop-daemon.sh start namenode
$
$ jps # 查看是否启动成功
4016 Jps
2556 NameNode
然后在另一台未格式化的namenode节点,即slave1执行:1
2$ cd /home/hadoop/hadoop-2.7.3/
$ ./bin/hdfs namenode -bootstrapStandby
然后停掉所有服务,在master下执行:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16$ cd /home/hadoop/hadoop-2.7.3/
$ ./sbin/stop-dfs.sh
Stopping namenodes on [hadoop-host-master hadoop-host-slave-1]
hadoop-host-slave-1: no namenode to stop
hadoop-host-master: stopping namenode
hadoop-host-slave-1: no datanode to stop
hadoop-host-slave-2: no datanode to stop
hadoop-host-slave-3: no datanode to stop
Stopping journal nodes [hadoop-host-slave-1 hadoop-host-slave-2 hadoop-host-slave-3]
hadoop-host-slave-2: stopping journalnode
hadoop-host-slave-1: stopping journalnode
hadoop-host-slave-3: stopping journalnode
Stopping ZK Failover Controllers on NN hosts [hadoop-host-master hadoop-host-slave-1]
hadoop-host-slave-1: no zkfc to stop
hadoop-host-master: no zkfc to stop
在其中一个namenode上执行格式化ZKFC,我们在master中执行:1
2
3
4
5
6
7
8$ cd /home/hadoop/hadoop-2.7.3/
$ ./bin/hdfs zkfc -formatZK
$
18/12/30 12:54:52 INFO ha.ActiveStandbyElector: Session connected.
18/12/30 12:54:52 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/hadoop-cluster-ha in ZK.
18/12/30 12:54:52 INFO zookeeper.ClientCnxn: EventThread shut down
18/12/30 12:54:52 INFO zookeeper.ZooKeeper: Session: 0x167fd5512250000 closed
再次启动集群的时候,不需执行上面的操作,直接执行如下命令即可,我们在master上面执行如下命令:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17$ cd /home/hadoop/hadoop-2.7.3/
$ ./sbin/start-dfs.sh
$
Starting namenodes on [hadoop-host-master hadoop-host-slave-1]
hadoop-host-slave-1: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-hadoop-host-slave-1.out
hadoop-host-master: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-hadoop-host-master.out
hadoop-host-slave-2: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-hadoop-host-slave-2.out
hadoop-host-slave-1: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-hadoop-host-slave-1.out
hadoop-host-slave-3: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-hadoop-host-slave-3.out
Starting journal nodes [hadoop-host-slave-1 hadoop-host-slave-2 hadoop-host-slave-3]
hadoop-host-slave-2: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-hadoop-host-slave-2.out
hadoop-host-slave-1: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-hadoop-host-slave-1.out
hadoop-host-slave-3: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-hadoop-host-slave-3.out
Starting ZK Failover Controllers on NN hosts [hadoop-host-master hadoop-host-slave-1]
hadoop-host-slave-1: starting zkfc, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-zkfc-hadoop-host-slave-1.out
hadoop-host-master: starting zkfc, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-zkfc-hadoop-host-master.out
它会自动启动namenode、datanode、journalnode和zkfc,在启动的过程中观看日志,是个好习惯。
可以在实体机的浏览器中输入:
http://hadoop-host-master:50070/
http://hadoop-host-slave-1:50070/
来查看是否启动成功,如无意外的话,你会看到如下结果页面。其中一个是active,另一个是standby:


我们在active节点的页面上切换tab到Datanodes可以看到有3个datanode节点,如下图所示:

切换到Utilities -> Browse the file system,如下图所示(只能在active节点的页面中查看,standby节点对HDFS没有READ权限):

从上面的界面可以看到,目前HDFS中没有任何文件。我们尝试往其中放一个文件,就将我们的hadoop的压缩包放进去,在active的namenode节点中执行如下操作:1
2
3
4
5
6$ cd /home/hadoop/hadoop-2.7.3/
$ ./bin/hdfs dfs -put /home/hadoop/Downloads/hadoop-2.7.3.tar.gz /
$ ./bin/hdfs dfs -ls /
Found 1 items
-rw-r--r-- 3 hadoop supergroup 214092195 2018-12-29 22:07 /hadoop-2.7.3.tar.gz
我们在图形界面中查看,如下图:

我们点击列表中的文件,将会显示它的数据具体分布在哪些节点上,如下图:

注意:在主节点执行start-dfs.sh,主节点的用户名必须和所有从节点的用户名相同。因为主节点服务器以这个用户名去远程登录到其他从节点的服务器中,所以在所有的生产环境中控制同一类集群的用户一定要相同。
验证failover,即验证两个namenode是否可以自动切换
我们将active的namenode kill掉,在active的namenode节点上面执行:1
2
3
4
5
6
7$ jps
2593 QuorumPeerMain
31444 Jps
30613 NameNode
30965 DFSZKFailoverController
$ kill -9 30613
我们kill掉之后发现standby无法自动切换到active。我们查看日志,发现:
/home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-zkfc-hadoop-host-slave-1.log
有如下内容:
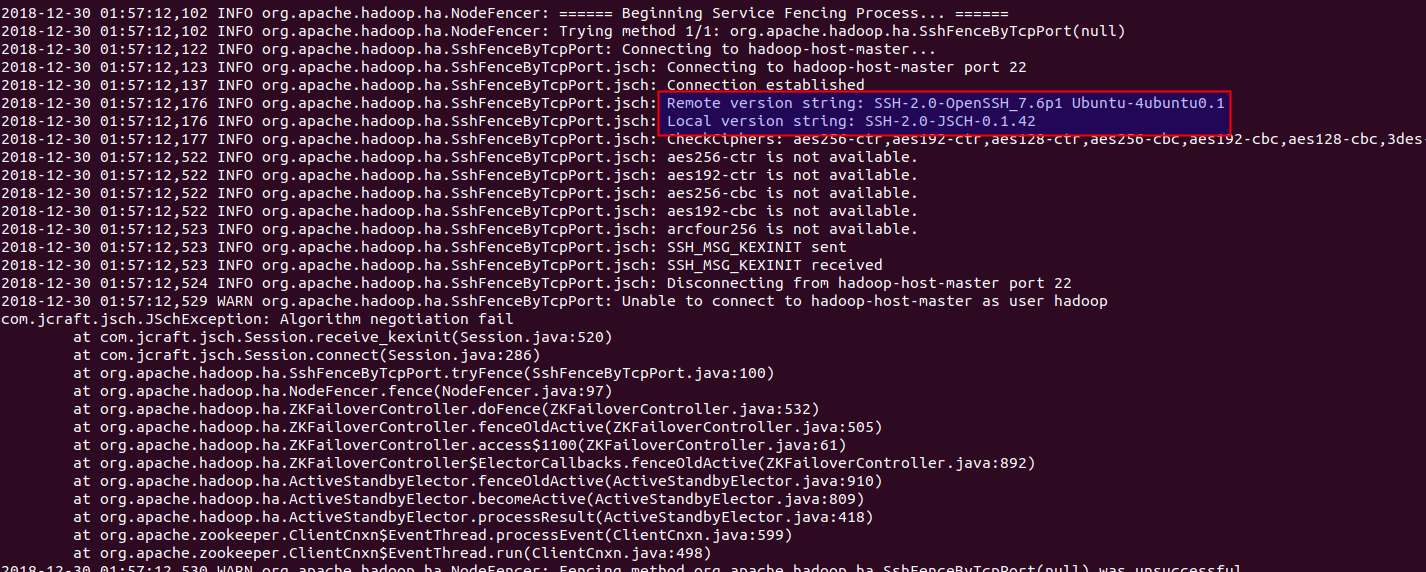
结论:两个namenode节点无法自动切换,的原因是操作系统安装的openssh版本和hadoop内部使用的版本不匹配造成的。
解决方案:将$HADOOP_HOME/share目录下的jsch-0.1.42.jar升级到jsch-0.1.54.jar,重启集群,问题解决。
我们首先到maven中央仓库下载jsch-0.1.54.jar:
https://mvnrepository.com/artifact/com.jcraft/jsch/0.1.54
我们只需将两个namenode中的jsch-0.1.42.jar升级到jsch-0.1.54.jar即可:1
2
3
4
5
6
7$ cd /home/hadoop/hadoop-2.7.3/
$ find ./ -name "*jsch*"
$
./share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib/jsch-0.1.42.jar
./share/hadoop/common/lib/jsch-0.1.42.jar
./share/hadoop/tools/lib/jsch-0.1.42.jar
./share/hadoop/kms/tomcat/webapps/kms/WEB-INF/lib/jsch-0.1.42.jar
从查询结果看,只有4个JAR包需要升级,我们只要将两个namenode节点中的JAR包替换即可。重启集群,再次验证failover,我们可以看到两个namenode已经可以自动切换。大功告成。
启动YARN
YARN的启动步骤和hadoop 集群的搭建一样,这里不再赘述。
active和standby之间的手动切换
有时候,我们需要手动将某个namenode设置为active,可以通过haadmin命令,相关用法如下(我一般的做法是将原来active的namenode断网,从而让standby的节点成为active,然后再将之前断网的机器连回网络):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28$ cd /home/hadoop/hadoop-2.7.3
$ ./bin/hdfs haadmin --help
-help: Unknown command
Usage: haadmin
[-transitionToActive [--forceactive] <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
$ ./bin/hdfs haadmin -getServiceState nn1
standby
$ ./bin/hdfs haadmin -getServiceState nn2
active
$ ./bin/hdfs haadmin -transitionToActive --forcemanual nn1