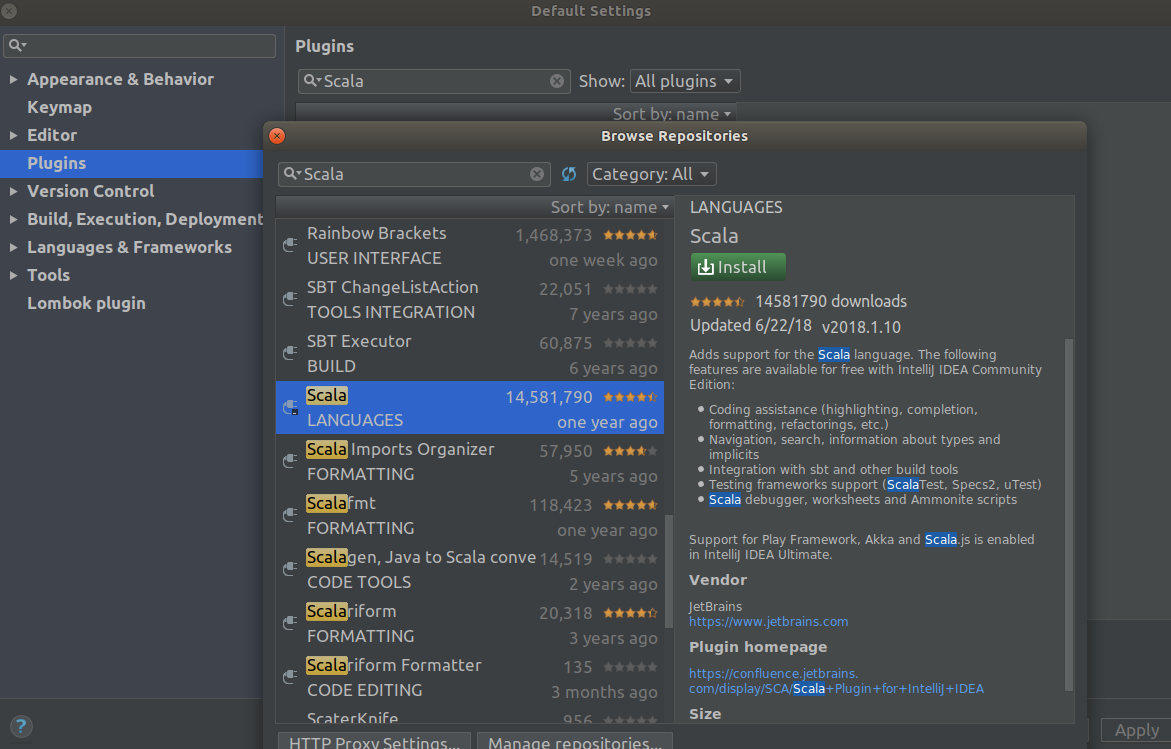
SHOW VARIABLES LIKE 'server_id';
SHOW VARIABLES LIKE 'log_%';
SHOW VARIABLES LIKE 'binlog_format';
创建 canal 链接 mysql 的账号,并分配作为 mysql slave 的权限,如果已有账户则可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
canal.instance.mysql.slaveId=1234 # mysql serverId , v1.0.26+ will autoGen canal.instance.master.address=127.0.0.1:3306 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 canal.instance.filter.regex=.*\\..*
启动canal
1 2
$ cd ~/canal $ sh bin/startup.sh
查看 server 日志
1 2 3 4 5 6 7
$ more logs/canal/canal.log
2021-01-22 20:12:11.735 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler 2021-01-22 20:12:11.797 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations 2021-01-22 20:12:11.813 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server. 2021-01-22 20:12:11.869 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[172.18.0.1(172.18.0.1):11111] 2021-01-22 20:12:13.779 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......
查看 instance 的日志
1 2 3 4 5 6 7 8 9 10 11 12 13 14
$ more logs/example/example.log
2021-01-22 20:12:12.428 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties] 2021-01-22 20:12:12.436 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties] 2021-01-22 20:12:12.722 [main] WARN o.s.beans.GenericTypeAwarePropertyDescriptor - Invalid JavaBean property 'connectionCharset' being accessed! Ambiguous write methods found next to actually used [public void com.alibaba.otter.canal.parse.inbound.mysql.AbstractMysqlEventParser.setConnectionCharset(java.nio.charset.Charset)]: [public void com.alibaba.otter.canal.parse.inbound.mysql.AbstractMysqlEventParser.setConnectionCharset(java.lang.String)] 2021-01-22 20:12:12.803 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties] 2021-01-22 20:12:12.803 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties] 2021-01-22 20:12:13.524 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example 2021-01-22 20:12:13.536 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$ 2021-01-22 20:12:13.536 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : 2021-01-22 20:12:13.570 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful.... 2021-01-22 20:12:13.801 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position 2021-01-22 20:12:13.801 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status 2021-01-22 20:12:15.240 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000003,position=4,serverId=1,gtid=<null>,timestamp=1591628633000] cost : 1408ms , the next step is binlog dump
$ tar xf spark-2.4.4-bin-hadoop2.7.tgz $ cd spark-2.4.4-bin-hadoop2.7/ $ ./sbin/start-master.sh
启动后,在启动日志中可以看到部分输出,如下:
20/01/14 16:54:24 INFO Master: Starting Spark master at spark://hadoop-host-slave-3:7077
20/01/14 16:54:24 INFO Master: Running Spark version 2.4.4
20/01/14 16:54:25 INFO Utils: Successfully started service 'MasterUI' on port 8080.
20/01/14 16:54:25 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://hadoop-host-slave-3:8080
20/01/14 16:54:25 INFO Master: I have been elected leader! New state: ALIVE
接着分别在slave1、slave2中启动spark作为从节点
1 2 3
$ tar xf spark-2.4.4-bin-hadoop2.7.tgz $ cd spark-2.4.4-bin-hadoop2.7/ $ ./sbin/start-slave.sh spark://hadoop-host-slave-3:7077
Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:6540fc08ee6e6b7b63468dc3317e3303aae178cb8a45ed3123180328bcc1d20f Status: Downloaded newer image for hello-world:latest
Hello from Docker! This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal.
To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/
For more examples and ideas, visit: https://docs.docker.com/get-started/
$ sudo docker logs d7c1549c2a495499270eb31819ce5e9ea9748ab8126f025f33b06612491fd447 hello world hello world hello world hello world hello world
查看正在运行中的容器
1 2 3
$ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d7c1549c2a49 ubuntu:18.04 "/bin/sh -c 'while t…" 4 minutes ago Up 4 minutes friendly_minsky
Options: --config string Location of client config files (default "/home/hewentian/.docker") -c, --context string Name of the context to use to connect to the daemon (overrides DOCKER_HOST env var and default context set with "docker context use") -D, --debug Enable debug mode -H, --host list Daemon socket(s) to connect to -l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info") --tls Use TLS; implied by --tlsverify --tlscacert string Trust certs signed only by this CA (default "/home/hewentian/.docker/ca.pem") --tlscert string Path to TLS certificate file (default "/home/hewentian/.docker/cert.pem") --tlskey string Path to TLS key file (default "/home/hewentian/.docker/key.pem") --tlsverify Use TLS and verify the remote -v, --version Print version information and quit
Commands: attach Attach local standard input, output, and error streams to a running container build Build an image from a Dockerfile commit Create a new image from a container's changes cp Copy files/folders between a container and the local filesystem create Create a new container deploy Deploy a new stack or update an existing stack diff Inspect changes to files or directories on a container's filesystem events Get real time events from the server exec Run a commandin a running container export Export a container's filesystem as a tar archive history Show the history of an image images List images import Import the contents from a tarball to create a filesystem image info Display system-wide information inspect Return low-level information on Docker objects kill Kill one or more running containers load Load an image from a tar archive or STDIN login Log in to a Docker registry logout Log out from a Docker registry logs Fetch the logs of a container pause Pause all processes within one or more containers port List port mappings or a specific mapping for the container ps List containers pull Pull an image or a repository from a registry push Push an image or a repository to a registry rename Rename a container restart Restart one or more containers rm Remove one or more containers rmi Remove one or more images run Run a command in a new container save Save one or more images to a tar archive (streamed to STDOUT by default) search Search the Docker Hub for images start Start one or more stopped containers stats Display a live stream of container(s) resource usage statistics stop Stop one or more running containers tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE top Display the running processes of a container unpause Unpause all processes within one or more containers update Update configuration of one or more containers version Show the Docker version information wait Block until one or more containers stop, then print their exit codes Run 'docker COMMAND --help' for more information on a command.
$ sudo docker search httpd NAME DESCRIPTION STARS OFFICIAL AUTOMATED httpd The Apache HTTP Server Project 2567 [OK] centos/httpd 23 [OK] centos/httpd-24-centos7 Platform for running Apache httpd 2.4 or bui… 22 armhf/httpd The Apache HTTP Server Project 8 polinux/httpd-php Apache with PHP in Docker (Supervisor, CentO… 3 [OK]
REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu 18.04 3556258649b2 5 days ago 64.2MB hello-world latest fce289e99eb9 6 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
列出本机上所有已创建的容器
1 2 3 4 5 6 7 8 9 10 11 12 13
$ sudo docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ee4b72860ab3 ubuntu:18.04 "/bin/sh -c 'while t…" 8 minutes ago Up 8 minutes brave_edison 3063341debf2 ubuntu:18.04 "/bin/bash" 9 minutes ago Exited (0) 9 minutes ago friendly_poitras 6623f20692a4 ubuntu:18.04 "/bin/echo 'Hello wo…" 9 minutes ago Exited (0) 9 minutes ago intelligent_roentgen a2d42ce3df7d training/webapp "python app.py" 2 hours ago Exited (137) 48 minutes ago epic_pasteur 1058cf5fafad training/webapp "python app.py" 2 hours ago Exited (137) 2 hours ago goofy_lewin 2c113cc40c51 training/webapp "python app.py" 2 hours ago Exited (137) 2 hours ago confident_gagarin c9102f1d9541 training/webapp "python app.py" 3 hours ago Exited (137) 2 hours ago crazy_borg a4e84d331fbd hello-world "/hello" 6 hours ago Exited (0) 6 hours ago epic_fermi b03a6f03bd39 hello-world "/hello" 2 days ago Exited (0) 2 days ago competent_cartwright b7c3f4699549 hello-world "/hello" 2 days ago Exited (0) 2 days ago crazy_brattain bb7eb9e197b4 hello-world "/hello" 2 days ago Exited (0) 2 days ago pensive_lalande
$ sudo docker ps -l CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d23dc5d88f11 ubuntu:18.04 "/bin/bash" 2 minutes ago Exited (0) About a minute ago amazing_vaughan
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2 2bdf86d10fbc 6 seconds ago 91MB ubuntu 18.04 3556258649b2 5 days ago 64.2MB hello-world latest fce289e99eb9 6 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
然后,我们就可以使用我们新建的镜像创建容器了
1 2 3 4 5 6 7
$ sudo docker run -it hewentian/ubuntu:v2 /bin/bash root@10adcace776b:/# cat /proc/version Linux version 4.15.0-47-generic (buildd@lgw01-amd64-001) (gcc version 7.3.0 (Ubuntu 7.3.0-16ubuntu3)) #50-Ubuntu SMP Wed Mar 13 10:44:52 UTC 2019 root@10adcace776b:/# whoami root root@10adcace776b:/# exit exit
FROM ubuntu:18.04 MAINTAINER hewentian "wentian.he@qq.com"
ENV AUTHOR="hewentian" WORKDIR /tmp/ RUN /usr/bin/touch he.txt RUN /bin/echo"The author is $AUTHOR, created at " >> /tmp/he.txt RUN /bin/date >> /tmp/he.txt
Sending build context to Docker daemon 2.56kB Step 1/7 : FROM ubuntu:18.04 ---> 3556258649b2 Step 2/7 : MAINTAINER hewentian "wentian.he@qq.com" ---> Running in 9684fd7dab36 Removing intermediate container 9684fd7dab36 ---> 87f25ba61a99 Step 3/7 : ENV AUTHOR="hewentian" ---> Running in 22e933129053 Removing intermediate container 22e933129053 ---> 23c5a574b01c Step 4/7 : WORKDIR /tmp/ ---> Running in a4341dbc2164 Removing intermediate container a4341dbc2164 ---> 94663075f2b0 Step 5/7 : RUN /usr/bin/touch he.txt ---> Running in e54479ffd964 Removing intermediate container e54479ffd964 ---> a196207c63e9 Step 6/7 : RUN /bin/echo"The author is $AUTHOR, created at " >> /tmp/he.txt ---> Running in 89d010bd1b78 Removing intermediate container 89d010bd1b78 ---> 11aa9b6d3605 Step 7/7 : RUN /bin/date >> /tmp/he.txt ---> Running in 66627425d24c Removing intermediate container 66627425d24c ---> c6cd98aa1461 Successfully built c6cd98aa1461 Successfully tagged hewentian/ubuntu:v2.1
查看生成的镜像
1 2 3 4 5 6 7
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 c6cd98aa1461 43 seconds ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 18 hours ago 91MB ubuntu 18.04 3556258649b2 6 days ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
用我们新建的镜像创建容器
1 2 3 4 5 6 7 8 9
$ sudo docker run -it hewentian/ubuntu:v2.1 /bin/bash
root@335d56425694:/tmp# ls /tmp/ he.txt root@335d56425694:/tmp# more /tmp/he.txt The author is hewentian, created at Tue Jul 30 03:10:50 UTC 2019 root@335d56425694:/tmp# exit exit
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 c6cd98aa1461 4 hours ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 22 hours ago 91MB nginx latest e445ab08b2be 6 days ago 126MB ubuntu 18.04 3556258649b2 6 days ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
使用nginx的默认配置来启动一个容器:
1 2 3
$ sudo docker run --name nginx-test -p 8081:80 -d nginx
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to docker nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p>
<p>For online documentation and support please refer to <ahref="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <ahref="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p> </body> </html>
$ sudo docker search mysql $ sudo docker pull mysql:5.6.42
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 c6cd98aa1461 4 hours ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 22 hours ago 91MB nginx latest e445ab08b2be 6 days ago 126MB ubuntu 18.04 3556258649b2 6 days ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB mysql 5.6.42 27e29668a08a 12 months ago 256MB
$ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 524097ed5349 mysql:5.6.42 "docker-entrypoint.s…" 3 minutes ago Up 3 minutes 0.0.0.0:3306->3306/tcp mysql-hwt
进入mysql,将root用户密码修改,并且禁用root远程登录
1 2 3 4 5
$ sudo docker exec -it mysql-hwt mysql -uroot -p123456
mysql> GRANT ALL ON *.* TO 'root'@'localhost' IDENTIFIED BY 'root'; mysql> DELETE FROM mysql.user WHERE User='root' AND Host NOT IN ('localhost', '127.0.0.1', '::1'); mysql> FLUSH PRIVILEGES;
$ sudo docker exec -it mongo mongo MongoDB shell version v4.2.7 connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb Implicit session: session { "id" : UUID("81ad33aa-6318-4854-98df-9910a8927698") } MongoDB server version: 4.2.7 Welcome to the MongoDB shell. For interactive help, type"help". For more comprehensive documentation, see http://docs.mongodb.org/ Questions? Try the support group http://groups.google.com/group/mongodb-user > use admin switched to db admin > > > db.createUser({user:"admin",pwd:"12345",roles:["root"]}) Successfully added user: { "user" : "admin", "roles" : [ "root" ] } > > > show collections Warning: unable to run listCollections, attempting to approximate collection names by parsing connectionStatus > > > db.auth("admin","12345") 1 > > show collections system.users system.version >
以交互模式进入容器 $ sudo docker exec -it 3063341debf2 /bin/bash root@3063341debf2:/# ls a.sh bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var root@3063341debf2:/# sh a.sh Wed Jul 31 01:44:34 UTC 2019 root@3063341debf2:/# exit exit
退出后,容器并不会停止 $ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3063341debf2 ubuntu:18.04 "/bin/bash" 41 hours ago Up 18 seconds friendly_poitras
另外,使用attach命令也能进入容器,但是当退出后,容器会停止
1 2 3 4 5 6 7 8 9 10 11 12 13 14
$ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3063341debf2 ubuntu:18.04 "/bin/bash" 41 hours ago Up 18 seconds friendly_poitras
$ sudo docker attach --sig-proxy=false 3063341debf2 root@3063341debf2:/# ls a.sh bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var root@3063341debf2:/# sh a.sh Wed Jul 31 02:02:50 UTC 2019 root@3063341debf2:/# exit exit
$ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
将镜像导出/导入
导出镜像语法:
1 2 3 4 5 6 7 8
$ sudo docker save --help
Usage: docker save [OPTIONS] IMAGE [IMAGE...]
Save one or more images to a tar archive (streamed to STDOUT by default)
Options: -o, --output string Write to a file, instead of STDOUT
导入镜像语法:
1 2 3 4 5 6 7 8 9
$ sudo docker load --help
Usage: docker load [OPTIONS]
Load an image from a tar archive or STDIN
Options: -i, --input string Read from tar archive file, instead of STDIN -q, --quiet Suppress the load output
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> c6cd98aa1461 27 hours ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 45 hours ago 91MB nginx latest e445ab08b2be 7 days ago 126MB ubuntu 18.04 3556258649b2 7 days ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> c6cd98aa1461 27 hours ago 64.2MB nginx latest e445ab08b2be 7 days ago 126MB ubuntu 18.04 3556258649b2 7 days ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> c6cd98aa1461 27 hours ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 45 hours ago 91MB nginx latest e445ab08b2be 7 days ago 126MB ubuntu 18.04 3556258649b2 7 days ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 c389673d68c5 5 seconds ago 66.6MB hewentian/ubuntu v2 2bdf86d10fbc 45 hours ago 91MB nginx latest e445ab08b2be 7 days ago 126MB ubuntu 18.04 3556258649b2 7 days ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
Log in to a Docker registry. If no server is specified, the default is defined by the daemon.
Options: -p, --password string Password --password-stdin Take the password from stdin -u, --username string Username
登出语法:
1 2 3 4 5 6
$ sudo docker logout --help
Usage: docker logout [SERVER]
Log out from a Docker registry. If no server is specified, the default is defined by the daemon.
登录/登出示例:
1 2 3 4 5 6 7 8 9 10 11
$ sudo docker login -u hewentian Password: WARNING! Your password will be stored unencrypted in /home/hewentian/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
$ sudo docker logout Removing login credentials for https://index.docker.io/v1/
将本地镜像上传到镜像仓库
默认上传到docker官方仓库docker.io,上传到私有仓库的例子,后面会介绍。
1 2 3 4
$ sudo docker push hewentian/ubuntu:v2.1 The push refers to repository [docker.io/hewentian/ubuntu] 8c29bfccf50c: Pushed v2.1: digest: sha256:992cc4e008449d8285387fe80aff3c9b0574360fc3ad21b04bccc5b6a4229923 size: 528
$ cd /home/hadoop $ wget https://storage.googleapis.com/harbor-releases/release-1.8.0/harbor-offline-installer-v1.8.2-rc1.tgz $ tar xf harbor-offline-installer-v1.8.2-rc1.tgz $ cd harbor $ ls harbor.v1.8.2.tar.gz harbor.yml install.sh LICENSE prepare
$ sudo docker login harbor.hewentian.com -u hewentian Password: WARNING! Your password will be stored unencrypted in /home/hewentian/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 3712fd008024 8 days ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 10 days ago 91MB nginx latest e445ab08b2be 2 weeks ago 126MB ubuntu 18.04 3556258649b2 2 weeks ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
例如我们要将ubuntu:18.04上传到harbor
1 2 3 4
$ sudo docker push harbor.hewentian.com/hp/ubuntu:18.04 [sudo] password for hewentian: The push refers to repository [harbor.hewentian.com/hp/ubuntu] An image does not exist locally with the tag: harbor.hewentian.com/hp/ubuntu
可以看到,不能直接上传,要先为待上传的镜像打tag
1 2 3 4 5 6 7 8 9 10 11
$ sudo docker tag ubuntu:18.04 harbor.hewentian.com/hp/ubuntu:18.04
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 3712fd008024 8 days ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 10 days ago 91MB nginx latest e445ab08b2be 2 weeks ago 126MB harbor.hewentian.com/hp/ubuntu 18.04 3556258649b2 2 weeks ago 64.2MB ubuntu 18.04 3556258649b2 2 weeks ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 3712fd008024 8 days ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 10 days ago 91MB nginx latest e445ab08b2be 2 weeks ago 126MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE hewentian/ubuntu v2.1 3712fd008024 8 days ago 64.2MB hewentian/ubuntu v2 2bdf86d10fbc 10 days ago 91MB nginx latest e445ab08b2be 2 weeks ago 126MB harbor.hewentian.com/hp/ubuntu 18.04 3556258649b2 2 weeks ago 64.2MB hello-world latest fce289e99eb9 7 months ago 1.84kB training/webapp latest 6fae60ef3446 4 years ago 349MB
今天一看,天哪,原来已经有4个月没有更新博客了,我在想,这4个月我都干嘛去了,内心立马慌起来了(你知道的,程序员是不能停止学习的)。但是细想,虽然没更新博客,但还是看了几本书:《从0到1》、《毛泽东选集》卷一、《MongoDB in Action》、《SpringBoot in Action》、《白帽子讲Web安全》,内心立马淡定了不少。好了,题外话不多说了,马上进入主题。
$ tar xf nginx-1.16.0.tar.gz $ cd nginx-1.16.0/ $ ls auto CHANGES CHANGES.ru conf configure contrib html LICENSE man README src
$ sudo ./configure --with-http_stub_status_module --with-http_ssl_module --with-http_realip_module checking for OS + Linux 4.15.0-39-generic x86_64 ...
中间省略部分
Configuration summary + using system PCRE library + OpenSSL library is not used + using system zlib library
nginx: the configuration file /usr/local/nginx/conf/nginx.conf syntax is ok nginx: configuration file /usr/local/nginx/conf/nginx.conf test is successful
Options: -?,-h : this help -v : show version and exit -V : show version and configure options thenexit -t : test configuration and exit -T : test configuration, dump it and exit -q : suppress non-error messages during configuration testing -s signal : send signal to a master process: stop, quit, reopen, reload -p prefix : set prefix path (default: /usr/local/nginx/) -c filename : set configuration file (default: conf/nginx.conf) -g directives : set global directives out of configuration file
private String getRealIP(HttpServletRequest request){ for (String head : Arrays.asList("X-Forwarded-For", "X-Real-IP")) { String ip = request.getHeader(head);
if (StringUtils.isBlank(ip)) { continue; }
log.info("{} : {}", head, ip);
int index = ip.indexOf(','); if (index != -1) { ip = ip.substring(0, index); }
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables – billions of rows X millions of columns – atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Configuring the maximum number of file descriptors and processes for the user who is running the HBase process is an operating system configuration, rather than an HBase configuration. It is also important to be sure that the settings are changed for the user that actually runs HBase. To see which user started HBase, and that user’s ulimit configuration, look at the first line of the HBase log for that instance.
$ cd /home/hadoop/ $ tar xzvf hbase-1.2.6-bin.tar.gz $ $ cd hbase-1.2.6/ $ ls bin CHANGES.txt conf docs hbase-webapps LEGAL lib LICENSE.txt NOTICE.txt README.txt
$ cd /home/hadoop/hbase-1.2.6/conf $ vi hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop-host-master:8020/hbase</value> <description>Do not create the dir hbase, the system will create it automatically, and the value is dfs.namenode.rpc-address.hadoop-cluster-ha.nn1</description> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> <description>Property from ZooKeeper's config zoo.cfg. The port at which the clients will connect.</description> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop-host-master,hadoop-host-slave-1,hadoop-host-slave-2</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/zookeeper-3.4.6/data</value> <description>Property from ZooKeeper's config zoo.cfg. The directory where the snapshot is stored.</description> </property> </configuration>
配置regionservers
在将要运行regionservers的节点加入此文件中
1 2 3 4 5 6
$ cd /home/hadoop/hbase-1.2.6/conf $ vi regionservers
$ cd /home/hadoop/hbase-1.2.6/ $ ./bin/hbase shell 2019-01-23 19:16:36,118 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable HBase Shell; enter 'help<RETURN>'for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
hbase(main):001:0> list TABLE 0 row(s) in 0.6030 seconds
=> []
由上述结果可知,Hbase中现在没有一张表。我们尝试创建一张表t_student:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
hbase(main):002:0> create 't_student', 'cf1' 0 row(s) in 2.4700 seconds
=> Hbase::Table - t_student hbase(main):003:0> list TABLE t_student 1 row(s) in 0.0250 seconds
hbase(main):008:0> flush 't_student' 0 row(s) in 0.7290 seconds
然后我们可以在HDFS、Hbase的管理界面分别看到表信息:
当我们在HDFS中看到表中的某个块的数据,如下:
我们可以通过Hbase中的命令来查看数据的真实内容:
1 2 3 4 5 6
$ cd /home/hadoop/hbase-1.2.6 $ ./bin/hbase hfile -p -f /hbase/data/default/t_student/b76cccf6c6a7926bf8f40b4eafc6991e/cf1/2ed0a233411447778982edce04e96fe3 2019-01-23 19:45:33,200 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2019-01-23 19:45:34,046 INFO [main] hfile.CacheConfig: Created cacheConfig: CacheConfig:disabled K: 01/cf1:name/1548242390794/Put/vlen=3/seqid=4 V: tim Scanned kv count -> 1
查看集群状态和节点数量
1 2
hbase(main):009:0> status 1 active master, 1 backup masters, 3 servers, 0 dead, 1.0000 average load
根据条件查询数据
1 2 3 4
hbase(main):010:0> get 't_student', '01' COLUMN CELL cf1:name timestamp=1548242390794, value=tim 1 row(s) in 0.0590 seconds
master.ServerManager: Waiting for region servers count to settle; currently checked in 0, slept for 855041 ms, expecting minimum of 1, maximum of 2147483647, timeout of 4500 ms, interval of 1500 ms.
[HBase] ERROR:org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
hive的官方文档中有对hive的详细介绍,这里不再赘述。我们用一句话描述如下: The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
mysql> CREATE DATABASE IF NOT EXISTS hive COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8'; mysql> GRANT ALL ON hive.* TO 'hive'@'%' IDENTIFIED BY 'hive'; mysql> GRANT ALL ON hive.* TO 'hive'@'localhost' IDENTIFIED BY 'hive'; mysql> FLUSH PRIVILEGES;
然后配置hive使用mysql存储元数据:
1 2
$ cd /home/hadoop/apache-hive-1.2.2-bin/conf/ $ vi hive-site.xml
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://mysql.hewentian.com:3306/hive</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>Username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property>
$ cd /home/hadoop/apache-hive-1.2.2-bin/bin $ ./hive
启动的时候可能会报如下错误:
Exception in thread "main" java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at org.apache.hadoop.fs.Path.initialize(Path.java:205)
at org.apache.hadoop.fs.Path.<init>(Path.java:171)
at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:659)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:582)
at org.apache.hadoop.hive.ql.session.SessionState.beginStart(SessionState.java:549)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:750)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
at java.net.URI.checkPath(URI.java:1823)
at java.net.URI.<init>(URI.java:745)
at org.apache.hadoop.fs.Path.initialize(Path.java:202)
... 12 more
解决方法如下,先建目录:
1 2
$ cd /home/hadoop/apache-hive-1.2.2-bin/ $ mkdir iotmp
<property> <name>hive.exec.local.scratchdir</name> <value>/home/hadoop/apache-hive-1.2.2-bin/iotmp/hadoop</value> <description>Local scratch space for Hive jobs</description> </property> <property> <name>hive.downloaded.resources.dir</name> <value>/home/hadoop/apache-hive-1.2.2-bin/iotmp/${hive.session.id}_resources</value> <description>Temporary local directory for added resources in the remote file system.</description> </property> <property> <name>hive.querylog.location</name> <value>/home/hadoop/apache-hive-1.2.2-bin/iotmp/hadoop</value> <description>Location of Hive run time structured log file</description> </property> <property> <name>hive.server2.logging.operation.log.location</name> <value>/home/hadoop/apache-hive-1.2.2-bin/iotmp/hadoop/operation_logs</value> <description>Top level directory where operation logs are stored if logging functionality is enabled</description> </property>
重新启动hive:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
$ cd /home/hadoop/apache-hive-1.2.2-bin/bin $ ./hive
Logging initialized using configuration in jar:file:/home/hadoop/apache-hive-1.2.2-bin/lib/hive-common-1.2.2.jar!/hive-log4j.properties hive> show databases; OK default Time taken: 0.821 seconds, Fetched: 1 row(s) hive> > use default; OK Time taken: 0.043 seconds hive> > show tables; OK Time taken: 0.094 seconds hive>
hive> CREATE DATABASE IF NOT EXISTS tim; OK Time taken: 0.323 seconds hive> > show databases; OK default tim Time taken: 0.025 seconds, Fetched: 2 row(s)
同样,我们可以在HDFS中查看到:
1 2 3 4
$ cd /home/hadoop/hadoop-2.7.3/ $ ./bin/hdfs dfs -ls /user/hive/warehouse Found 1 items drwxrwxr-x - hadoop supergroup 0 2019-01-01 19:32 /user/hive/warehouse/tim.db
hive> use tim; OK Time taken: 0.042 seconds hive> > CREATE TABLE IF NOT EXISTS t_user ( > id INT, > name STRING COMMENT 'user name', > age INT COMMENT 'user age', > sex STRING COMMENT 'user sex', > birthday DATE COMMENT 'user birthday', > address STRING COMMENT 'user address' > ) > COMMENT 'This is the use info table' > ROW FORMAT DELIMITED > FIELDS TERMINATED BY '\t' > STORED AS TEXTFILE; OK Time taken: 0.521 seconds hive> > show tables; OK t_user Time taken: 0.035 seconds, Fetched: 1 row(s) hive>
查看表结构
1 2 3 4 5 6 7 8 9 10
hive> desc t_user; OK id int name string user name age int user age sex string user sex birthday date user birthday address string user address Time taken: 0.074 seconds, Fetched: 6 row(s) hive>
hive> INSERT INTO TABLE t_user(id, name, age, sex, birthday, address) VALUES(1, 'Tim Ho', 23, 'M', '1989-05-01', 'Higher Education Mega Center South, Guangzhou city, Guangdong Province'); Query ID = hadoop_20190102160558_640a90a7-9122-4650-af78-acb436e2643b Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1546186928725_0015, Tracking URL = http://hadoop-host-master:8088/proxy/application_1546186928725_0015/ Kill Command = /home/hadoop/hadoop-2.7.3/bin/hadoop job -kill job_1546186928725_0015 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-02 16:06:08,341 Stage-1 map = 0%, reduce = 0% 2019-01-02 16:06:14,565 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.39 sec MapReduce Total cumulative CPU time: 1 seconds 390 msec Ended Job = job_1546186928725_0015 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to: hdfs://hadoop-cluster-ha/user/hive/warehouse/tim.db/t_user/.hive-staging_hive_2019-01-02_16-05-58_785_7094384272339204067-1/-ext-10000 Loading data to table tim.t_user Table tim.t_user stats: [numFiles=1, numRows=1, totalSize=96, rawDataSize=95] MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 1.39 sec HDFS Read: 4763 HDFS Write: 162 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 390 msec OK Time taken: 17.079 seconds hive>
hive> select * from t_user; OK 1 Tim Ho 23 M 1989-05-01 Higher Education Mega Center South, Guangzhou city, Guangdong Province Time taken: 0.196 seconds, Fetched: 1 row(s) hive> > select * from t_user where name='Tim Ho'; OK 1 Tim Ho 23 M 1989-05-01 Higher Education Mega Center South, Guangzhou city, Guangdong Province Time taken: 0.258 seconds, Fetched: 1 row(s) hive> > select count(*) from t_user; Query ID = hadoop_20190102161100_d60df721-539d-4e5b-a3db-a4951ac884b4 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1546186928725_0016, Tracking URL = http://hadoop-host-master:8088/proxy/application_1546186928725_0016/ Kill Command = /home/hadoop/hadoop-2.7.3/bin/hadoop job -kill job_1546186928725_0016 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-01-02 16:11:10,739 Stage-1 map = 0%, reduce = 0% 2019-01-02 16:11:16,997 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.05 sec 2019-01-02 16:11:23,280 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.37 sec MapReduce Total cumulative CPU time: 2 seconds 370 msec Ended Job = job_1546186928725_0016 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.37 sec HDFS Read: 7285 HDFS Write: 2 SUCCESS Total MapReduce CPU Time Spent: 2 seconds 370 msec OK 1 Time taken: 24.444 seconds, Fetched: 1 row(s) hive>
2 scott 25 M 1977-10-21 USA 3 tiger 21 F 1977-08-12 UK
然后在hive中执行LOAD命令:
1 2 3 4 5 6 7 8 9 10 11 12 13
hive> LOAD DATA LOCAL INPATH '/home/hadoop/user.txt' INTO TABLE t_user; Loading data to table tim.t_user Table tim.t_user stats: [numFiles=2, numRows=0, totalSize=151, rawDataSize=0] OK Time taken: 0.214 seconds hive> > select * from t_user; OK 1 Tim Ho 23 M 1989-05-01 Higher Education Mega Center South, Guangzhou city, Guangdong Province 2 scott 25 M 1977-10-21 USA 3 tiger 21 F 1977-08-12 UK Time taken: 0.085 seconds, Fetched: 3 row(s) hive>
$ cd /home/hadoop/hadoop-2.7.3/ $ ./bin/hdfs namenode -bootstrapStandby
然后停掉所有服务,在master下执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$ cd /home/hadoop/hadoop-2.7.3/ $ ./sbin/stop-dfs.sh
Stopping namenodes on [hadoop-host-master hadoop-host-slave-1] hadoop-host-slave-1: no namenode to stop hadoop-host-master: stopping namenode hadoop-host-slave-1: no datanode to stop hadoop-host-slave-2: no datanode to stop hadoop-host-slave-3: no datanode to stop Stopping journal nodes [hadoop-host-slave-1 hadoop-host-slave-2 hadoop-host-slave-3] hadoop-host-slave-2: stopping journalnode hadoop-host-slave-1: stopping journalnode hadoop-host-slave-3: stopping journalnode Stopping ZK Failover Controllers on NN hosts [hadoop-host-master hadoop-host-slave-1] hadoop-host-slave-1: no zkfc to stop hadoop-host-master: no zkfc to stop
在其中一个namenode上执行格式化ZKFC,我们在master中执行:
1 2 3 4 5 6 7 8
$ cd /home/hadoop/hadoop-2.7.3/ $ ./bin/hdfs zkfc -formatZK $
18/12/30 12:54:52 INFO ha.ActiveStandbyElector: Session connected. 18/12/30 12:54:52 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/hadoop-cluster-ha in ZK. 18/12/30 12:54:52 INFO zookeeper.ClientCnxn: EventThread shut down 18/12/30 12:54:52 INFO zookeeper.ZooKeeper: Session: 0x167fd5512250000 closed
再次启动集群的时候,不需执行上面的操作,直接执行如下命令即可,我们在master上面执行如下命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
$ cd /home/hadoop/hadoop-2.7.3/ $ ./sbin/start-dfs.sh $
Starting namenodes on [hadoop-host-master hadoop-host-slave-1] hadoop-host-slave-1: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-hadoop-host-slave-1.out hadoop-host-master: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-hadoop-host-master.out hadoop-host-slave-2: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-hadoop-host-slave-2.out hadoop-host-slave-1: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-hadoop-host-slave-1.out hadoop-host-slave-3: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-hadoop-host-slave-3.out Starting journal nodes [hadoop-host-slave-1 hadoop-host-slave-2 hadoop-host-slave-3] hadoop-host-slave-2: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-hadoop-host-slave-2.out hadoop-host-slave-1: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-hadoop-host-slave-1.out hadoop-host-slave-3: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-hadoop-host-slave-3.out Starting ZK Failover Controllers on NN hosts [hadoop-host-master hadoop-host-slave-1] hadoop-host-slave-1: starting zkfc, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-zkfc-hadoop-host-slave-1.out hadoop-host-master: starting zkfc, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-zkfc-hadoop-host-master.out
Generic options supported are -conf <configuration file> specify an application configuration file -D <property=value> use value for given property -fs <local|namenode:port> specify a namenode -jt <local|resourcemanager:port> specify a ResourceManager -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is bin/hadoop command [genericOptions] [commandOptions]