首先,你必须有一台redis服务器可以使用,如果还没安装,可以参考我的上一篇 redis 的安装使用
使用JAVA API来操作Redis的例子可以在这里找到:RedisUtil.java、RedisDemo.java
部分笔记摘自《Redis 实战》,它总结得很好。
Redis默认16个数据库,并以数字为索引,从0开始到15,可以手工修改这个配置,增加数量。登录的时候,默认为0库。
Redis与其他数据库的对比
高性能键值缓存服务器memcached也经常被拿来与Redis进行比较:这两者都可以用于存储键值映射,彼此的性能也相关无几,但是Redis能够自动以两种不同的方式将数据写入硬盘,并且Redis除了能存储普通的字符串之外,还可以存储其他4种数据结构,而memcached只能存储普通的字符串键。这些不同之处使得Redis可以用于解决更为广泛的问题,并且既可以用作主数据库(primary database)使用,又可以作为其他存储系统的辅助数据库(auxiliary database)使用。
| 名称 | 类型 | 数据存储选项 | 查询类型 | 附加功能 |
|---|---|---|---|---|
| Redis | 使用内存存储的非关系数据库 | 字符串、列表、集合、散列表、有序集合 | 每种数据类型都有自已的专属命令,另外还有批量操作(bulk operation)和不完全(partial)的事务支持 | 发布与订阅,主从复制(master/slave replication),持久化,脚本(存储过程,stored procedure) |
| memcached | 使用内存存储的键值缓存 | 键值之间的映射 | 创建命令、读取命令、更新命令、删除命令以及其他几个命令 | 为提升性能而设的多线程服务器 |
| Mysql | 关系数据库 | 每个数据库可以包含多个表,每个表可以包含多个行;可以处理多个表的视图(view);支持空间(spatial)和第三方扩展 | SELECT、INSERT、UPDATE、DELETE、函数、存储过程 | 支持ACID性质(需要使用InnoDB),主从复制,主主复制(master/master replication) |
| PostgreSQL | 关系数据库 | 每个数据库可以包含多个表,每个表可以包含多个行;可以处理多个表的视图(view);支持空间(spatial)和第三方扩展;支持可定制类型 | SELECT、INSERT、UPDATE、DELETE、内置函数、自定义存储过程 | 支持ACID性质,主从复制,由第三方支持的多主复制(multi-master replication) |
| MongoDB | 使用硬盘存储的非关系文档存储 | 每个数据库可以包含多个表,每个表可以包含多个无schema(schema-less)的BSON文档 | 创建命令、读取命令、更新命令、删除命令、条件查询命令等 | 支持 map-reduce 操作,主从复制,分片,空间索引(spatial index) |
Redis提供的5种结构
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| STRING | 可以是字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作,对整数和浮点数执行自增或者自减操作 |
| LIST | 一个链表,链表上的每个节点都包含了一个字符串 | 从链表的两端推入或者弹出元素;根据偏移量对链表进行修剪;读取单个或者多个元素;根据值查找或者移除元素 |
| SET | 包含字符串的无序收集器,并且被包含的每个字符串都是独一无二、各不相同的 | 添加、获取、移除单个元素;检查一个元素是否存在于集合中;计算交集、并集、差集;从集合里面随机获取元素 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对;获取所有键值对 |
| ZSET(有序集合) | 字符串成员与浮点数分值之间的有序映射,元素的排列顺序由分值的大小决定 | 添加、获取、删除单个元素;根据分值范围或者成员来获取元素 |
在实际中最好还是让主服务器只使用50%~65%的内存,留下30%~45%的内存用于执行BGSAVE命令和创建记录写命令的缓冲区。
当所有成员的分值都相同时,有序集合将根据成员的名字来进行排序;而当所有成员的分值都是0的时候,成员将按照字符串的二进制顺序进行排序。
对于大部分数据库来说,插入行操作的执行速度非常快(插入行只会在硬盘文件末尾进行写入)。不过,对表里面的行进行更新却是一个速度相当慢的操作,因为这种更新除了会引起一次随机读(random read)之外,还可能会引起一次随机写(random write)。
使用cookie实现购物车–也就是将整个购物车都存储到cookie里面的做法非常常见,这种做法的一大优点是无须对数据库进行写入就可以实现购物车功能,而缺点则是程序需要重新解析和验证cookie,确保cookie的格式正确,并且包含的商品都是真正可购买的商品。cookie购物车还有一个缺点:因为浏览器每次发送请求都会连cookie一起发送,所以如果购物车cookie的体积比较大,那么请求发送和处理的速度可能会有所降低。
如果用户对一个不存在的键或者一个保存了空串的键执行自增或者自减操作,那么Redis在执行操作时会将这个键的值当作是0来处理。如果用户尝试对一个值无法被解释为整数或者浮点数的字符串键执行自增或者自减操作,那么Redis将向用户返回一个错误。
Redis不支持嵌套结构特性
Redis的基本事务
Redis的基本事务(basic transaction)需要用到MULTI命令和EXEC命令,这种事务可以让一个客户端在不被其他客户端打断的情况下执行多个命令。和关系数据库那种可以在执行的过程中进行回滚(rollback)的事务不同,在Redis里面,被MULTI命令和EXEC命令包围的所有命令会一个接一个地执行,直到所有命令都执行完毕为止。当一个事务执行完毕之后,Redis才会处理其他客户端的命令。
要在Redis里面执行事务,我们首先需要执行MULTI命令,然后输入那些我们想要在事务里面执行的命令,最后再执行EXEC命令。当Redis从一个客户端那里接收到MULTI命令时,Redis会将这个客户端之后发送的所有命令都放入到一个队列里面,直到这个客户端发送EXEC命令为止,然后Redis就会在不被打断的情况下,一个接一个地执行存储在队列里面的命令。从语义上来说,Redis事务在Python客户端上面是由流水线(pipeline)实现的:对连接对象调用pipeline()方法将创建一个事务,在一切正常的情况下,客户端会自动地使用MULTI和EXEC包裹起用户输入的多个命令。此外,为了减少Redis与客户端之间的通信往返次数,提升执行多个命令时的性能,Python的Redis客户端会存储起事务包含的多个命令,然后在事务执行时一次性地将所有命令都发送给Redis。
持久化选项
Redis提供了两种不同的持久化方法来将数据存储到硬盘里面。一种方法叫快照(snapshotting),它可以将存在于某一时刻的所有数据都写入硬盘里面。另一种方法叫只追加文件(append-only file, AOF),它会在执行写命令时,将被执行的写命令复制到硬盘里面。这两种持久化方法既可以同时使用,又可以单独使用,在某些情况下甚至可以两种方法都不使用。
为了防止Redis因为创建子进程而出现停顿,我们可以考虑关闭自动保存,转而通过手动发送BGSAVE或者SAVE来进行持久化。手动发送BGSAVE一样会引起停顿,唯一不同的是用户可以通过手动发送BGSAVE命令来控制停顿出现的时间。另一方面,虽然SAVE会一直阻塞Redis直到快照生成完毕,但是因为它不需要创建子进程,所以就不会像BGSAVE一样因为创建子进程而导致Redis停顿;并且因为没有子进程在争抢资源,所以SAVE创建快照的速度会比BGSAVE创建快照的速度要来得更快一些。
配置AOF持久化机制
修改redis配置文件,增加如下配置。1
2
3
4
5
6
7
8
9$ vi {REDIS_HOME}/redis.conf
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
然后重启redis即可。可以登录redis,然后使用命令config get *查看配置。
创建快照的办法有以下几种
- 客户端可以通过向Redis发送BGSAVE命令来创建一个快照;
- 客户端还可以通过向Redis发送SAVE命令来创建一个快照,接到SAVE命令的Redis服务器在快照创建完毕之前将不再响应任何其他命令;
- 用户设置save配置选项;
- 当Redis通过SHUTDOWN命令接收到关闭服务器的请求时,或者接收到标准TERM信号时,会执行一个SAVE命令;
- 当一个Redis服务器连接另一个Redis服务器,并向对方发送SYNC命令来开始一次复制操作的时候,如果主服务器目前没有在执行BGSAVE操作,或者主服务器并非刚刚执行完BGSAVE操作,那么主服务器就会执行BGSAVE命令。
在只使用快照持久化来保存数据时,一定要记住:如果系统真的发生崩溃,用户将丢失最近一次生成快照之后更改的所有数据。因此,快照持久化只适用于那些即使丢失一部分数据也不会造成问题的应用程序。
当Redis存储的数据量只有几个GB的时候,使用快照来保存数据是没有问题的。Redis会创建子进程并将数据保存到硬盘里面,生成快照所需的时间比你读这句话所需的时间还要短。但随着Redis占用的内存越来越多,BGSAVE在创建子进程时耗费的时间也会越来越多。如果Redis的内存占用量达到数十个GB,并且剩余的空闲内存并不多,或者Redis运行在虚拟机上面,那么执行BGSAVE可能会导致系统长时间地停顿,也可能引发系统大量地使用虚拟内存,从而导致Redis的性能降低至无法使用的程度。
AOF持久化会将被执行的写命令写到AOF文件的末尾,以此来记录数据发生的变化。因此,Redis只要从头到尾重新执行一次AOF文件包含的所有写命令,就可以恢复AOF文件所记录的数据集。通过appendonly yes配置选项来打开。
Redis每秒同步一次AOF文件时的性能和不使用任何持久化特性时的性能相关无几,而通过每秒同步一次AOF文件,Redis可以保证,即使出现系统崩溃,用户也最多只会丢失一秒之内产生的数据。
因为Redis会不断地将被执行的写命令记录到AOF文件里面,所以随着Redis不断运行,AOF文件的体积也会不断增长,在极端情况下,体积不断增大的AOF文件甚至可能会用完硬盘的所有可用空间。还有另一个问题就是,因为Redis在重启之后需要通过重新执行AOF文件记录的所有写命令来还原数据集,所以如果AOF文件的体积非常大,那么还原操作执行的时间就可能会非常长。为了解决AOF文件体积不断增大的问题,用户可以向Redis发送BGREWRITEAOF命令,这个命令会通过移除AOF文件中的冗余命令来重写(rewrite)AOF文件,使AOF文件的体积变得尽可能地小。
关系数据库通常会使用一个主服务器(master)向多个从服务器(slave)发送更新,并使用从服务器来处理所有读请求。在Redis中开启从服务器所必须的选项只有slaveof一个。通过向从服务器发送SLAVEOF no one命令,我们可以让这个从服务器断开与主服务器的连接。因为Redis的主服务器和从服务器并没有特别不同的地方,所以从服务器也可以拥有自已的从服务器,并由此形成主从链(master/slave chaining),如下图: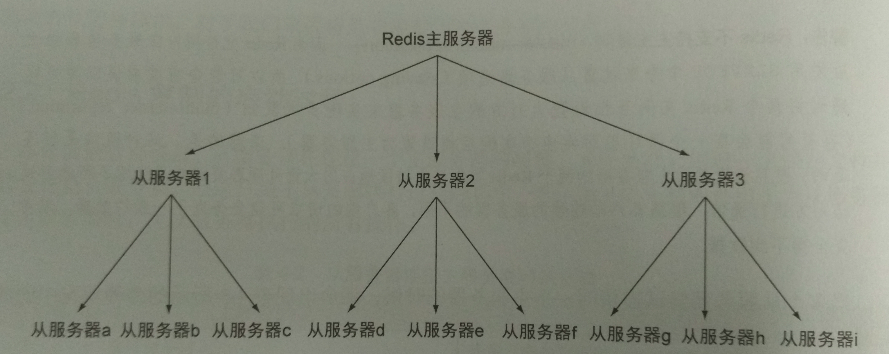
解决从服务器重同步(resync)问题的其中一个方法,就是减少主服务器需要传送给从服务器的数据数量,这可以通过构建像上图所示的树状复制中间层来完成。除了构建树状的从服务器群组之外,解决从服务器重同步问题的另一个方法就是对网络连接进行压缩,从而减少需要传送的数据量。一些Redis用户就发现使用带压缩的SSH隧道(tunnel)进行连接可以明显地降低带宽占用,如果使用这个方法,记得使用SSH提供的选项来让SSH连接在断线后自动进行连接。
提升Redis读取能力的最简单方法,就是添加只读从服务器。在使用只读从服务器的时候,请务必记得只对Redis主服务器进行写入。在默认情况下,尝试对一个被配置为从服务器的Redis服务器进行写入将引发一个错误(就算这个从服务器是其他从服务器的主服务器,也是如此)。不过,可以通过设置配置选项使从服务器也能执行写入操作,不过由于这一功能通常都处于关闭状态,所以对从服务器进行写入一般都会引发错误。使用多个Redis从服务器处理读查询时可能会遇到的最棘手的问题,就是主服务器临时下线或者永久下线。
Redis Sentinel可以配合Redis的复制功能使用,并对下线的主服务器进行故障转移。
分布式锁
一般来说,在对数据进行“加锁”时,程序首先需要通过获取(acquire)锁来得到对数据进行排他性访问的能力,然后才能对数据进行一系列的操作,最后还要将锁释放(release)给其他程序。对于能够被多个线程访问的共享内存数据结构来说,这种“先获取锁,然后执行操作,最后释放锁”的动作非常常见。Redis使用WATCH命令来代替对数据进行加锁,因为WATCH只会在数据被其他客户端抢先修改了的情况下通知执行了这个命令的客户端,而不会阻止其他客户端对数据进行修改,所以这个命令被称为乐观锁(optimistic locking)。
分布式锁也有类似的“首先获取锁,然后执行操作,最后释放锁”动作,但这种锁既不是给同一个进程中的多个线程使用,也不是给同一台机器上的多个进程使用,而是由不同机器上的不同Redis客户端进行获取和释放锁的。
我们没有直接使用操作系统级别的锁、编程语言级别的锁,或者其他各式各样的锁,而是选择了花费大量时间去使用Redis构建锁,这其中一个原因和范围有关:为了对Redis存储的数据进行排他性访问,客户端需要访问一个锁,这个锁必须定义在一个可以让所有客户端都看得见的范围之内,而这个范围就是Redis本身,因此我们需要把锁构建在Redis里面。另一方面,虽然Redis提供SETNX命令确实具有基本的加锁功能,但它的功能并不完整,并且也不具备分布式锁常见的一些高级特性,所以我们还是需要自已动手来构建分布式锁。
WATCH、MULTI和EXEC组成的事务并不具有可扩展性,原因在于程序在尝试完成一个事务的时候,可能会因为事务执行失败而反复地进行重试。保证数据的正确性是一件非常重要的事情,但使用WATCH命令的做法并不完美 。为了解决这个问题,我们将使用锁。
因为客户端即使在使用锁的过程中也可能会因为这样或那样的原因而下线,所以为了防止客户端在取得锁之后崩溃,并导致锁一直处于“已被获取”的状态,最终版的锁实现将带有超时限制特性:如果获得锁的进程未能在指定的时限内完成操作,那么锁将自动被释放。下面列出了一些导致锁出现不正确实行为的原因,也及锁在不正确运行时的症状:
- 持有锁的进程因为操作时间过长而导致锁被自动释放,但进程本身并不知晓这一点,甚至还可能会错误地释放掉了其他进程持有的锁;
- 一个持有锁并打算执行长时间操作的进程已经崩溃,但其他想要获取锁的进程不知道哪个进程持有着锁,也无法检测出持有锁的进程已经崩溃,只能白白地浪费时间等待锁被释放;
- 在一个进程持有的锁过期之后,其他多个进程同时尝试去获取锁,并且都获得了锁;
- 上面提到的第一种情况和第三种情况同时出现,导致有多个进程获得了锁,而每个进程都以为自已是唯一一个获得锁的进程。
在高负载情况下,使用锁可以减少重试次数、降低延迟时间、提升性能并将加锁的粒度调整至合适的大小。
一般来说,当程序使用一个来自Redis的值去构建另一个将要被添加到Redis里面的值时,就需要使用锁或者由WATCH、MULTI和EXEC组成的事务来消除竞争条件。
计数信号量
计数信号量是一种锁,它可以让用户限制一项资源最多能够同时被多少个进程访问,通常用于限定能够同时使用的资源数量。你可以把我们在前一节创建的锁看作是只能被一个进程访问的信号量。计数信号量和其他锁的区别在于,当客户端获取锁失败的时候,客户端通常会选择进行等待;而当客户端获取计数信号量失败的时候,客户端通常会选择立即返回失败结果。
以下是之前介绍过的各个信号量实现的优缺点:
- 如果你对于使用系统时钟没有意见,也不需要对信号量进行刷新,并且能够接受信号量的数量偶尔超过限制,那么可以使用我们给出的第一个信号量实现;
- 如果你只信任差距在一两秒之间的系统时钟,但仍然能够接受信号量的数量偶尔超过限制,那么你可以使用第二个信号量实现;
- 如果你希望信号量一直都具有正确的行为,那么可以使用带锁的信号量实现来保证正确性。
消息拉取
两个或多个客户端在互相发送和接收消息的时候,通常会使用以下两种方法来传递消息。第一种被称为消息推送(push messaging),也就是由发送者来确保所有接收者已经成功接收到了消息。Redis内置了用于进行消息推送的PUBLISH命令和SUBSCRIBE命令。这两个命令有个缺陷:客户端必须一直在线才能接收到消息,断线可能会导致客户端丢失消息。第二种方法被称为消息拉取(pull messaging),这种方法要求接收者自已去获取存储在某种邮箱(mailbox)里面的消息。
索引相关
从文档里面提取单词的过程通常被称为语法分析(parsing)和标记化(tokenization),这个过程可以产生出一系列用于标识文档的标记(token),标记有时候又被称为单词(word)。标记化的一个常见的附加步骤,就是移除内容中的非用词(stop word)。非用词就是那些在文档中频繁出现但是却没有提供相应信息量的单词,对这些单词进行搜索将返回大量无用的结果。移除非用词不仅可以提高搜索性能,还可以减少索引的体积。
用户有些时候可能会想要使用多个具有相同意思的单词进行搜索,并把它们看作是同一个单词,我们把这样的单词称为同义词。
搜索程序在取得多个文档之后,通常还需要根据每个文档的重要性对它们进行排序–搜索领域把这一问题称为关联度计算问题。
广告相关
广告索引操作的特别之处在于它返回的不是一组广告或者一组搜索结果,而是单个广告;并且被索引的广告通常都拥有像位置、年龄或者性别这类必须的定向参数。
Web页面上展示的广告主要有3种类型:按展示次数计费(cost per view)、按点击次数计费(cost per click)和按动作执行次数计费(cost per action)。按展示次数计费的广告又称为CPM广告或按千次计费(cost per mile)广告,这种广告每展示1000次就需要收取固定的费用。按点击计费的广告又称为CPC广告,这种广告根据被点击的次数收取固定的费用。按动作执行次数计费的广告又称为CPA广告,这种广告根据用户在广告的目的地网站上执行的动作收取不同的费用。
让广告的价格保持一致:为了尽可能地简化广告价格的计算方式,程序将对所有类型的广告进行转换,使得它们的价格可以基于每千次展示进行计算,产生出一个估算CPM(estimated CPM),简称eCPM。对于CPM广告来说,因为这种广告已经给出了CPM价格,所以程序只要直接把它的CPM用作eCPM就可以了。至于CPC广告和CPA广告,程序则需要根据相应的规则为它们计算出eCPM。
优化Redis
降低Redis的内存占用有助于减少创建快照和加载快照所需的时间、提升载入AOF文件和重写AOF文件时的效率、缩短从服务器进行同步所需的时间,并且能让Redis存储更多的数据而无需添加额外的硬件。
在列表、散列和有序集合的长度较短或者体积较小的时候,Redis可以选择使用一种名为压缩列表(ziplist)的紧凑存储方式来存储这些结构。压缩列表会以序列化的方式存储数据,这些序列化数据每次被读取的时候都要进行解码,每次被写入的时候也要进行局部的重新编码,并且可能需要对内存里面的数据进行移动。
不同结构关于使用压缩列表表示的配置选项(我安装的是 4.0.11 版本),配置文件位于{REDIS_HOME}/redis.conf
# Hashes are encoded using a memory efficient data structure when they have a
# small number of entries, and the biggest entry does not exceed a given
# threshold. These thresholds can be configured using the following directives.
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
# Lists are also encoded in a special way to save a lot of space.
# The number of entries allowed per internal list node can be specified
# as a fixed maximum size or a maximum number of elements.
# For a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 Kb <-- not recommended for normal workloads
# -4: max size: 32 Kb <-- not recommended
# -3: max size: 16 Kb <-- probably not recommended
# -2: max size: 8 Kb <-- good
# -1: max size: 4 Kb <-- good
# Positive numbers mean store up to _exactly_ that number of elements
# per list node.
# The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size),
# but if your use case is unique, adjust the settings as necessary.
list-max-ziplist-size -2
# Sets have a special encoding in just one case: when a set is composed
# of just strings that happen to be integers in radix 10 in the range
# of 64 bit signed integers.
# The following configuration setting sets the limit in the size of the
# set in order to use this special memory saving encoding.
set-max-intset-entries 512
# Similarly to hashes and lists, sorted sets are also specially encoded in
# order to save a lot of space. This encoding is only used when the length and
# elements of a sorted set are below the following limits:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
说明:
- entries选项说明散列、集合和有序集合在被编码为压缩列表的情况下,允许包含的最大元素数量;
- value选项则说明了压缩列表每个节点的最大体积是多少个字节;
- 当上述两个选项的限制条件中的任意一个被突破的时候,Redis就会将相应的列表、散列或是有序集合从压缩列表编码转换为其他结构,而内存占用也会因此而增加;
- 当压缩列表被转换为普通的结构之后,即使结构将来重新满足配置选项设置的限制条件,结构也不会重新转换回压缩列表;
- 如果整数包含的所有成员都可以被解释为十进制整数,而这些整数又处于平台的有符号整数范围之内,并且集合成员的数量又足够少的话(上面有配置),那么Redis就会以有序整数数组的方式存储集合,这种存储方式又被称为整数集合(intset)。以有序数组的方式存储集合不仅可以降低内存消耗,还可以提升所有标准集合的执行速度。
缺点:读写一个长度较大的压缩列表可能会给性能带来负面的影响,随着紧凑结构的体积变得越来越大,操作这些结构的速度也会变得越来越慢。
让键名保持简短
到目前为止尚未提到的一件事,就是减少键长度的作用,这里所说的“键”包括所有数据库键、散列的域、集合和有序集合的成员以及所有列表的节点,键的长度越长,Redis需要存储的数据也就越多。
分片结构
分片本质上就是基于某些简单的规则将数据划分为更小的部分,然后根据数据所属的部分来决定将数据发送到哪个位置上面。
使用Lua来扩展Redis
使用Lua编程语言进行的服务器端脚本编程功能,这个功能可以让用户直接在Redis内部执行各种操作,从而达到简化代码并提高性能的作用。将脚本载入Redis需要用到一个名为SCRIPT LOAD的命令,这个命令接受一个字符串格式的Lua脚本为参数,它会把脚本存储起来等待之后使用,然后返回被存储脚本的SHA1校验和。之后,用户只要调用EVALSHA命令,并输入脚本的SHA1校验和以及脚本所需的全部参数就可以调用之前存储的脚本。
Lua版本的锁实现减少了加锁时所需的通信往返次数,所以Lua版本的锁实现在尝试获取锁时的速度比原版的锁要快得多。虽然Lua脚本可以提供巨大的性能优势,并且能在一些情况下大幅地简化代码,但是我们也要记住,运行在Redis内部的Lua脚本只能访问位于Lua脚本之内或者Redis数据库之内的数据,而锁或WATCH/MULTI/EXEC事务并没有这一限制。
Redis在将数据库持久化到硬盘的时候,需要用到fork系统调用,而Windows并不支持这个调用。在缺少fork调用的情况下,Redis在执行持久化操作期间就只能够阻塞所有客户端,直到持久化操作执行完毕为止。
查看一个对象的类型可以使用DEBUG OBJECT命令
127.0.0.1:6379> rpush test a b c d
(integer) 4
127.0.0.1:6379> DEBUG OBJECT test
Value at:0x7f6160c774e0 refcount:1 encoding:quicklist serializedlength:25 lru:9577083 lru_seconds_idle:44 ql_nodes:1 ql_avg_node:4.00 ql_ziplist_max:-2 ql_compressed:0 ql_uncompressed_size:23
127.0.0.1:6379>
redis命令行查看中文显示乱码
Redis在使用命令行操作时,如果查看内容中包含中文,会显示16进制的字符串\xe4\xbf\xa1\xe9\x98\xb3\xe5\xb8\x82\,为了正确显示中文,在启动客启端的时候,加上--raw参数即可:1
2
3$ ./redis-cli -h 127.0.0.1 --raw
127.0.0.1:6379> get city
广州






